

此前清華大學的 AI 團隊與國內人工智能初創公司麵壁智能訓練並開源了 MiniCPM 係列模型,這包括麵向圖文理解的多模態模型 MiniCPM-V 係列,這些模型在開源框架下供全球的 AI 研究團隊使用。
不過從 2024 年 5 月 29 日開始,自稱為斯坦福大學 Llama3-V 的人工智能團隊高調宣傳僅需 500 美元就可以訓練超越 OpenAI GPT-4V 的 SOTA 多模態模型。
兩名作者分別是 Siddharth Sharma 和 Aksh Garg (均為斯坦福大學計算機科學本科生),在高調宣傳的同時有網友發現他們推出的 Llama3-V 模型的結構和代碼與麵壁智能早前推出補救的 MiniCPM-Llama3-V2.5 非常類似,看起來僅對部分變量名稱進行了修改和替換。
該事件經過發酵後也引起了麵壁智能的關注,該公司發布回應證實斯坦福大學的這個項目確實和 MiniCPM 模型一樣,可以識別出清華簡(清華大學獲捐的戰果竹簡)戰國古文字,這部分古文字為研究團隊從清華簡上逐字掃描並經由人工標注得來。
斯坦福大學 Llama3-V 團隊的這種行為顯然已經屬於明顯的抄襲了,實際上 MiniCPM 提供開源模型,基於開源模型構建新模型是個很正常的操作,但如果隻是下載別人的模型簡單替換下名稱就說是自己訓練的,這就屬於抄襲行為了。
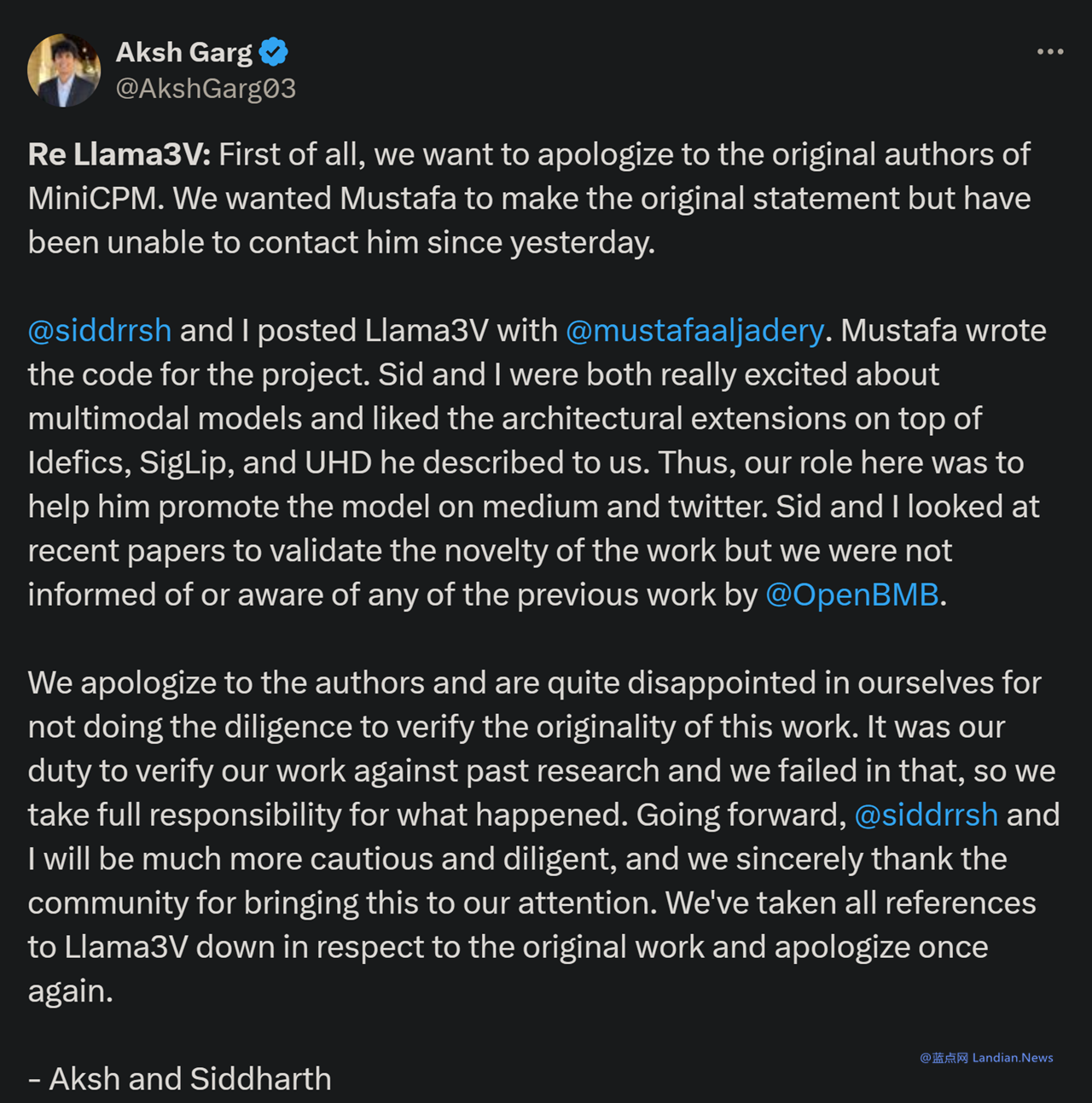
昨天夜裏抄襲的兩名成員在其 X/Twitter 賬號上發布致歉信,不過在致歉信中兩名成員指出他們引用的是另一名研究人員編寫的代碼,這名研究人員名為 Mustafa Aljadery。
於是這兩人幫助 Mustafa 在 Medium 和 X/Twitter 上推廣這個模型,他們自稱沒有完整盡職調查也就是沒有發現 Mustafa 發布的模型是抄襲麵壁智能的。
而 Mustafa 則將自己的 X/Twitter 設置為受保護狀態,沒有發布任何回應 (而且現在也處於失聯狀態),所以不清楚這是三人合謀還是兩人被 Mustafa 騙了。
限時活動推薦:阿裏雲服務器36元/年搶購、騰訊雲30M帶寬新加坡服務器、QQ超會15個月108元、B站大會員88元。







